Introduction
For a while, I had been making posts on Instagram with Diffusion AI (usually with Qwen Image Edit 1.0 and the Anime LoRA I trained for this model), and I wanted to make a video post someday. This opportunity finally came on February 25, 2026, when my desire to randomly make a video awakened; although I didn't know the subject of the video, a song was playing in my mind at that moment. So I decided to make a video related to the elementary school year-end show that the song belonged to, as a tribute. In other words, the topic would be about that day.
Discovering Source Material
After deciding on the video's topic, I searched through my personal archives and found a low-quality video of the 2008 year-end show. My initial goal was to redesign a miniature version or a scene of the elementary school show with a LoRA I trained for Qwen Image Edit 1.0, and to re-animate it with Wan 2.2. But the footage was so poor that this seemed impossible, and the only usable frames in the video appeared to be scenes projected onto a screen via a projector and guest visitors—though they weren't great quality either.
At that point, I decided to enhance the image quality with Qwen Image Edit 2511 (I couldn't remember how to use an upscaler and my last attempt had failed), redesign with Qwen Image Edit 1.0 + LoRA, then animate with Wan 2.2, using each video fragment as a "life frame", and to set the video's theme as "slice-of-life."
Production Stages
Each video fragment's preparation took 3 stages (each stage taking 15 minutes: image enhancement, anime conversion, animation) and 45 minutes in total, and with video editing, I completed it in 6 hours. At this stage, as is natural with diffusion models, some outputs failed at various stages, so the 6-hour timeframe was actually unnecessarily long for this phase. One of these failed outputs was the scene with the guest visitors.
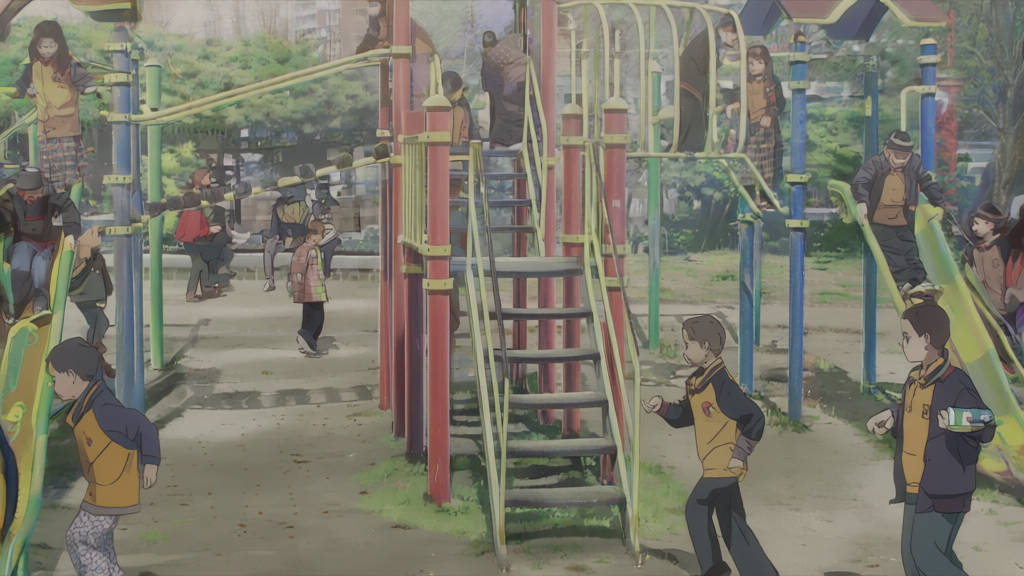
Face Correction Technique
The teacher sitting in the middle among the guest visitors initially came out with a badly rendered, melted face that could be described as "zombie-like." I didn't include the image in this post out of respect. This could have been a major problem and could have rendered that frame unusable, but the rest of the frame turned out beautifully and frankly, I didn't want it to go to waste.
So I tried a method that came to mind; first, I found a higher quality photo of that teacher, converted it to anime (with my own LoRA file), and replaced the teacher there with herself using Qwen Image Edit 2511. The result was flawless and natural.
Final Stage and Sharing
After preparing the videos, I recorded the actual song from my memory using Audacity and combined everything with OpenShot Editor, then shared it the same day. The post received quite a lot of likes—unexpectedly so for my standards—and became an inspiration for me to make another experimental video called "2015."